
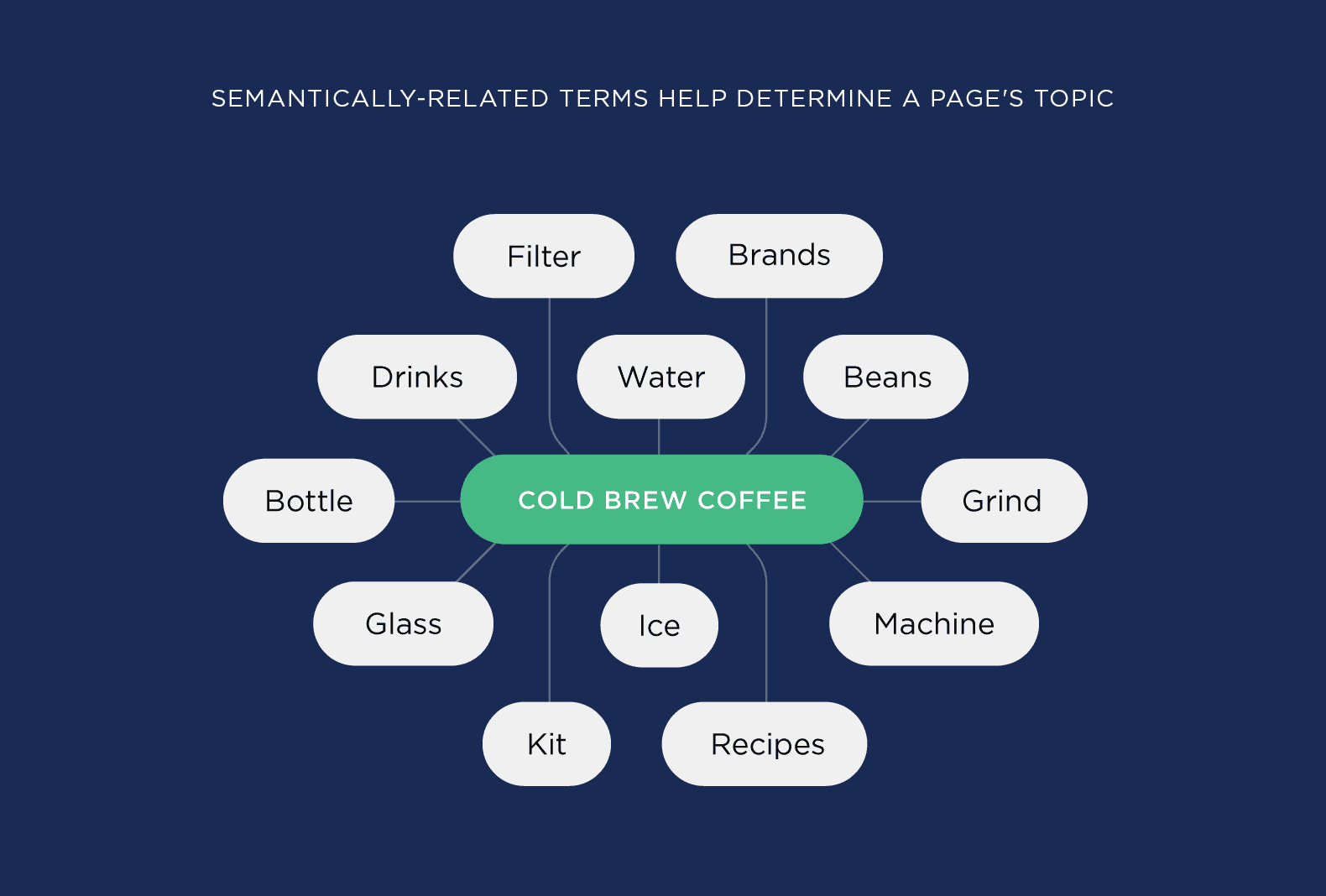
Latent Semantic Indexing, often abbreviated as LSI, is a mathematical method used primarily in natural language processing to uncover the hidden connections between words and their meanings. By analyzing the relationships among terms in large datasets, LSI helps search engines retrieve information more accurately, enhancing the user’s search experience.
Why Is Latent Semantic Indexing Important?
Understanding the significance of LSI can be a game-changer for content creators and marketers alike. Why, you ask? Here are a few key reasons:
- Enhanced Search Relevance: LSI improves the accuracy of search results by identifying and indexing not just synonyms but also related terms. When you write about “surprise” using LSI helps your content be associated with related phrases like “surprise party” or “outdoor games.” This context-rich approach leads to higher relevancy in search engine results.
- Better User Experience: A well-structured use of LSI keywords ensures that users find the content that aligns closely with their search intent. For instance, if someone searches for “how to make a surprise” an LSI-enhanced article can deliver the respective context, making it more likely to answer their query effectively.
In conclusion, LSI creates a bridge between user queries and relevant content, making it indispensable in the ever-evolving landscape of search engine optimization (SEO).
History of LSI
The history of LSI dates back to the late 1980s when researchers like Thomas K. Landauer and Susan T. Dumais formalized its theoretical foundations. Their work incorporated a mathematical technique called Singular Value Decomposition (SVD) to analyze word frequencies in documents. Key milestones in the history of LSI include:
- 1970s: Early theoretical advancements in multivariate statistical techniques.
- 1988: The initial patent for LSI technology was granted, marking a crucial leap.
- 1990: The first academic applications showcasing LSI’s potential began appearing in leading journals.
As the internet expanded, LSI’s relevance grew, influencing search engine algorithms and shaping how content is indexed and retrieved online, even as its direct application has evolved over time.
How Latent Semantic Indexing Works
Latent Semantic Indexing (LSI) operates on complex mathematical principles that unlock the hidden meanings behind text data. Understanding these concepts can demystify how LSI enhances information retrieval systems.
Mathematical Concepts
At the core of LSI lies Singular Value Decomposition (SVD), a method from linear algebra. This technique allows for the transformation of a large term-document matrix into smaller, more manageable sets without losing critical semantic relationships. Here’s how it works:
- Construction of a Term-Document Matrix (TDM): Each row represents unique terms, while each column represents individual documents. The entries in the matrix denote the frequency of terms in those documents.
- Applying SVD: This decomposes the TDM into three matrices: U, S, and V. The largest singular values in S capture the most significant relationships, allowing LSI to reduce the data’s dimensionality while maintaining its core semantic structure.
By stripping away noise from the data, LSI effectively retains essential information while facilitating efficient processing.
Application in Information Retrieval
LSI’s application in information retrieval is revolutionary. By establishing contextual relationships between words, it enables search engines to:
- Retrieve Relevant Documents: Even if the exact search terms aren’t present, LSI can identify documents that share similar contextual themes.
- Combat Synonymy: LSI helps address the issue where different words convey similar meanings, leading to more accurate search results.
In practice, when multiple users search for similar concepts, systems utilizing LSI can deliver results that more accurately reflect their inquiries, significantly enhancing user experience.
Latent Semantic Indexing FAQ
Does Google use latent semantic indexing?
While Google doesn’t explicitly utilize Latent Semantic Indexing (LSI) as a part of its algorithms, it incorporates similar principles. Google employs sophisticated machine learning techniques to understand context and relationships among words. This ensures that search results are relevant and aligned with user intent. The evolution of search algorithms means Google now focuses on a more comprehensive understanding of language rather than strictly adhering to synonym usage.
What is an LSI keyword?
An LSI keyword refers to words or phrases that are semantically related to a primary keyword. They provide context and meaning, helping search engines index content more effectively. For example, if your main keyword is “recipe,” LSI keywords might include “ingredients,” “cooking instructions,” and “dinner ideas.” Using these LSI keywords within your content can improve the relevance and visibility of your web pages.
What are LSI keywords examples?
Here are some examples of LSI keywords: – For “car,” LSI keywords could be “automobile,” “vehicle,” and “engine.” – For “fitness,” LSI keywords might include “exercise,” “health,” and “workout plans.”
How do I choose LSI keywords?
Choosing effective LSI keywords involves a few simple steps:
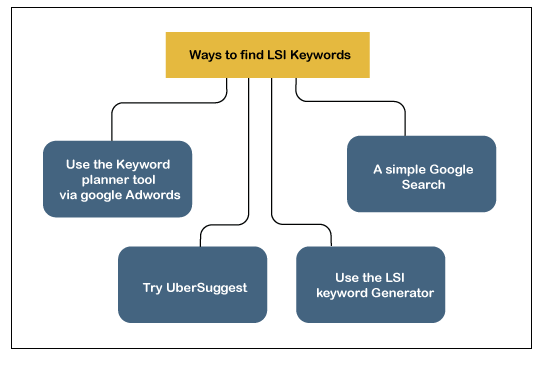
– Use Google Search: Begin typing your primary keyword in the search bar and observe the suggestions.
– Keyword Tools: Utilize tools like Google Keyword Planner or Ubersuggest to discover related keywords.
– Analyze Competitors: Examine top-ranking articles for your keyword and note common terms. By following these steps, you can enhance the relevance of your content, boosting its visibility and search engine rankings.
Latent Semantic Indexing vs. Other Information Retrieval Techniques
In the broad landscape of search engine optimization (SEO) and information retrieval, various techniques exist to analyze and rank content effectively. Among them, Latent Semantic Indexing (LSI) presents unique advantages and distinctions when compared to more traditional methods such as keyword-based algorithms and TF-IDF.
Comparison with Keyword-Based Methods
Keyword-based methods rely heavily on the frequency and presence of specific keywords within a document. While these methods can be effective, they often fail to capture the context and relationships between words, leading to potential misinterpretations of content. For example:
- Keyword Stuffing: Overemphasizing keywords can detract from content quality and penalize search rankings.
- Limited Understanding: These methods might match users to documents that contain the exact keywords without considering the intent behind the search query.
In contrast, LSI examines the contextual relationships among words, enabling search engines to deliver more relevant results based on underlying meanings rather than mere keyword frequency.
Contrast with TF-IDF Algorithms
TF-IDF (Term Frequency-Inverse Document Frequency) is another widely used information retrieval technique. This method highlights the importance of words in a document relative to their usage across a broader dataset. However, despite its effectiveness in gauging content relevance, TF-IDF does have limitations:
- Static Nature: TF-IDF treats each term individually, without acknowledging how words may relate semantically.
- Context Ignorance: It doesn’t consider the nuances of language or the relationships between multiple terms within a document.
LSI, on the other hand, offers a more dynamic understanding of language by capturing meaning through dimensionality reduction techniques like Singular Value Decomposition (SVD). This not only enhances the accuracy of search results but also aids in better comprehension of user intent—a crucial element in providing meaningful search experiences in today’s SEO environment.